5.1循环序列模型
觉得有用的话,欢迎一起讨论相互学习~
1.5不同类型的循环神经网络
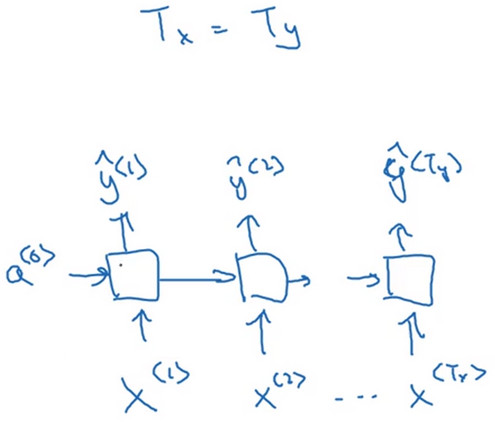
上节中介绍的是 具有相同长度输入序列和输出序列的循环神经网络,但是对于很多应用\(T_{x}和T_{y}\)并不一定相等。 在此节会介绍不同的能够处理不同问题的循环神经网络。
多对多循环神经网络
- 对于命名实体识别的问题中,RNN的输出和输入序列长度一致--\(T_{x}=T_{y}\)。
- 则在每读一个单词时都输出预测的值\(\hat{y}\)
这是一个典型的多对多的问题。
多对一循环神经网络
- 对于情感识别问题而言,RNN的输入是一段文本序列,输出是一个分类的评价--输出的是一个数值。
- 则只在输入整段文本后,在最后一个时间步进行预测,输出分类的结果,而不是每读入一个单词后输出结果。
这是一个典型的多对一问题。

一对多循环神经网络
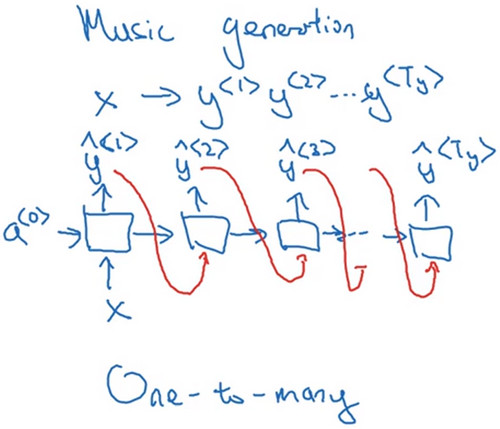
- 对于音乐生成问题而言,RNN的输入是一个数字或者一个单词,输出是一段音符。
- X通常是一个数字用于表示想要生成的音乐类型,或者是生成音乐的第一个音符,或者X也可以为空为0向量。
- 在第一个时间步输入X,再往后的时间步,不进行输入,但是输出随时间步的生成的音符,一直合成到这个音乐作品的最后一个音符。
在这个例子中,需要将生成的输出也作为输入传入下一层(如图红线所示)
输入和输出序列长度不等的循环神经网络
- 对于机器翻译的问题而言,输入句子的单词的数量和输出句子的单词的数量可能不同
- 通常在不同的时间步中依次读入输入序列,全部读完后,再输出RNN的结果,这样就可以使得RNN的输入序列长度和输出序列长度不同了。
这种网络可以被分为两个部分,其中前段部分被称为编码器“encoder”用于获取输入序列,后段部分被称为解码器“decoder”,其会读取所有输入然后输出翻译成其他语言的结果。

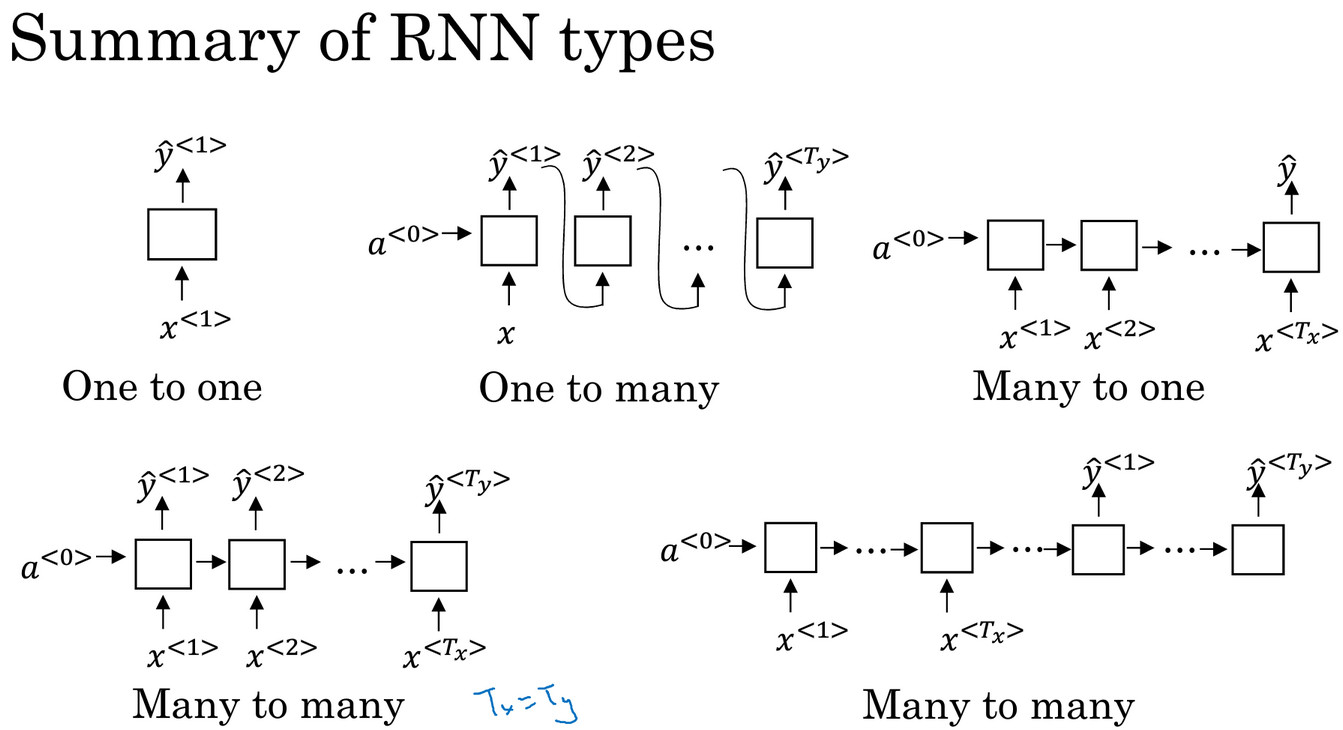
循环神经网络结构总结
1.6语言模型与序列生成Language model and sequence generation
语言模型
- 对于语音识别系统,当你听见一个句子“the apple and pear salad was delicious”,但是语句发音会让语音识别系统识别出下面两个句子:
- The apple and pair salad.(苹果和一对沙拉)
- The apple and pear salad.(苹果和梨沙拉)
- 句子的本意是输出下面的句子,但是由于1,2两句发音十分相似,并不能很好的识别1,2两句话.此时就需要语言模型--他能计算出这两句话各自的可能性。
语言模型能判断句子出现的概率
使用RNN建立语言模型
- 训练集: 对于一个语言模型而言首先需要一个很大的文本语料库--数量众多的英文句子组成的文本
- 对于语料库中的一个句子来说,首先按照单词将其标记成为一个个独立的单词,并且在句子末尾加上EOS符号用以表示一个完整的句子。
- 对于标点符号,可以自己认定所建立的语言模型中是否需要标记出标点符号。
- 如果训练集中有一些词并不在字典中,字典一般定义了最常用的词汇。例如:对于句子:"The Egyptian Mau is a bread of cat. "而言Mau是个不存在在字典中的词汇,此时将这个词标记为UNK--用于代表未知词。语言模型只针对UNK(unknown word)计算单词出现的概率而不是针对特定的Mau这个单词。
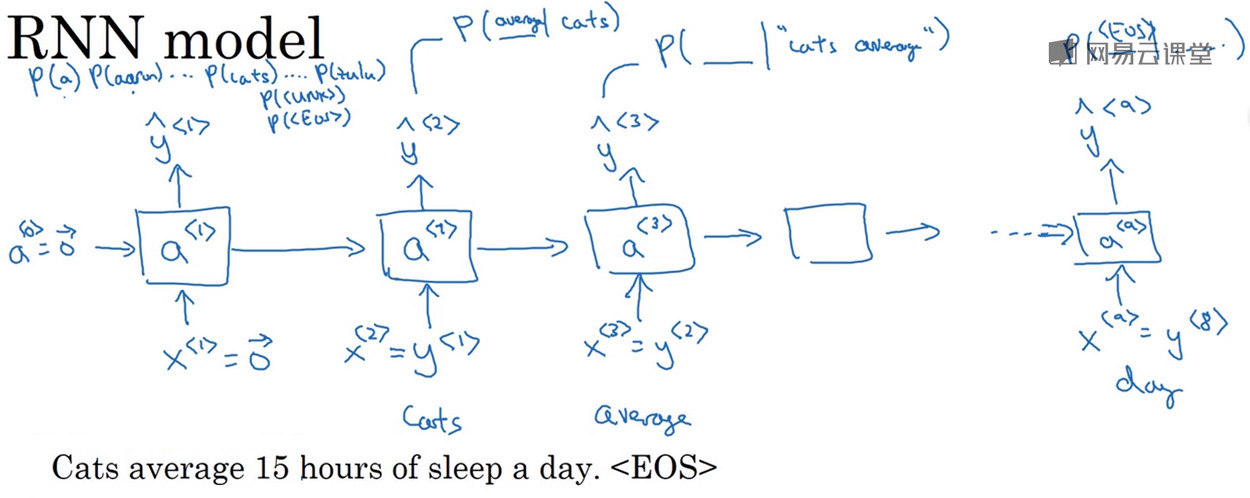
Cats average 15 hours of sleep a day.
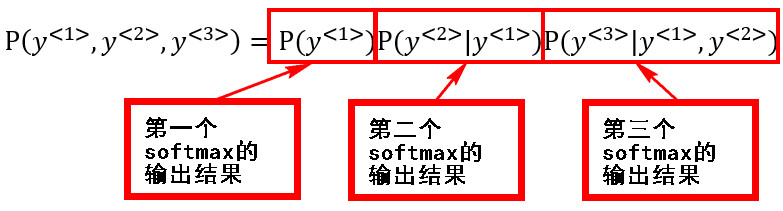
- 初始化\(X^{<1>}=\vec{0},a^{<0>}=\vec{0}\) 通过前向传播使用Softmax计算字典中各个单词出现的概率 输出字典中所有词的概率\(\hat{y}^{<1>}\)
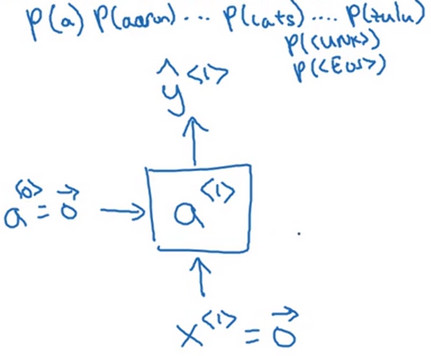
- 在第二时间步中,使用激活项\(a^{<1>}\),并且把正确的第一个单词cats传入作为\(y^{<1>}\)相当于告诉RNN模型第一个词的正确答案。然后计算出字典中各个词的概率\(\hat{y}^{<2>}\),相当于计算P( _ |"cats")
- 在第三时间步中,使用激活项\(a^{<2>}\),并且把正确的第而个单词average传入作为\(y^{<2>}\)相当于告诉RNN模型第二个词的正确答案。然后计算出字典中各个词的概率\(\hat{y}^{<3>}\),相当于计算P( _ |"cat average")
RNN损失函数
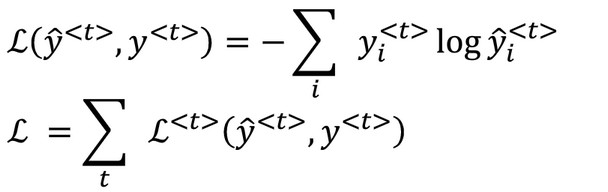
数学原理